Cryptography is the science to encrypt and decrypt data that enables the users to store sensitive information or transmit it across insecure networks so that it can be read only by the intended recipient.
Data which can be read and understood without any special measures is called plaintext, while the method of disguising plaintext in order to hide its substance is called encryption.
Encrypted plaintext is known as cipher text and process of reverting the encrypted data back to plain text is known as decryption.
The science of analyzing and breaking secure communication is known as cryptanalysis. The people who perform the same also known as attackers.
Cryptography can be either strong or weak and the strength is measured by the time and resources it would require to recover the actual plaintext.
Hence an appropriate decoding tool is required to decipher the strong encrypted messages.
There are some cryptographic techniques available with which even a billion computers doing a billion checks a second, it is not possible to decipher the text.
As the computing power is increasing day by day, one has to make the encryption algorithms very strong in order to protect data and critical information from the attackers.
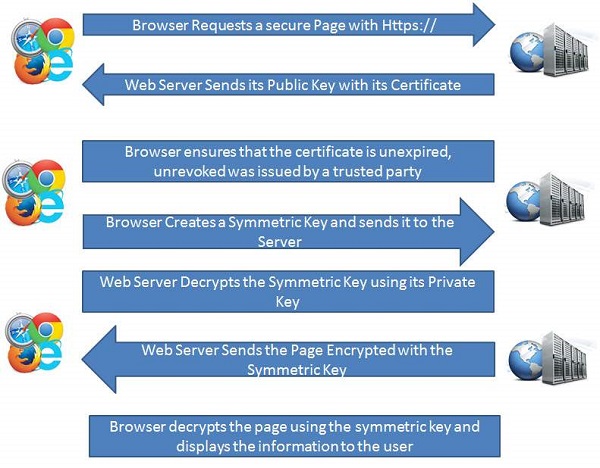
How Encryption Works?
A cryptographic algorithm works in combination with a key (can be a word, number, or phrase) to encrypt the plaintext and the same plaintext encrypts to different cipher text with different keys.
Hence, the encrypted data is completely dependent couple of parameters such as the strength of the cryptographic algorithm and the secrecy of the key.
Cryptography Techniques
Symmetric Encryption − Conventional cryptography, also known as conventional encryption, is the technique in which only one key is used for both encryption and decryption. For example, DES, Triple DES algorithms, MARS by IBM, RC2, RC4, RC5, RC6.
Asymmetric Encryption − It is Public key cryptography that uses a pair of keys for encryption: a public key to encrypt data and a private key for decryption. Public key is published to the people while keeping the private key secret. For example, RSA, Digital Signature Algorithm (DSA), Elgamal.
Hashing − Hashing is ONE-WAY encryption, which creates a scrambled output that cannot be reversed or at least cannot be reversed easily. For example, MD5 algorithm. It is used to create Digital Certificates, Digital signatures, Storage of passwords, Verification of communications, etc.