Thứ Ba, 25 tháng 12, 2018
Hacker là gì ? Làm gì để trở thành Hacker ?
Bản tóm tắt này không có sẵn. Vui lòng
nhấp vào đây để xem bài đăng.
Tìm hiểu về tấn công Man in the Middle – Chiếm quyền điểu khiển Session
Trong hai phần đầu của loạt bài giới thiệu về các tấn công man-in-the-middle này, chúng tôi đã giới thiệu cho các bạn về tấn công giả mạo ARP cache, giả mạo DNS. Như những gì chúng tôi đã giới thiệu trong các ví dụ đó, các tấn công MITM ra rất hiệu quả và rất khó bị phát hiện. Tuy nhiên trong phần ba của loạt bài này, chúng tôi sẽ giới thiệu thêm cho các bạn một cách tấn công mới, đó là tấn công chiếm quyền điều khiển session. Cũng như trong hai phần trước, chúng tôi sẽ giới thiệu một số lý thuyết và cách thức thực hiện tấn công cũng như cách phát hiện và biện pháp phòng chống.
Chiếm quyền điều khiển Session
Thuật ngữ chiếm quyền điều khiển session (session hijacking) chứa đựng một loạt các tấn công khác nhau. Nhìn chung, các tấn công có liên quan đến sự khai thác session giữa các thiết bị đều được coi là chiếm quyền điều khiển session. Khi đề cập đến một session, chúng ta sẽ nói về kết nối giữa các thiết bị mà trong đó có trạng thái đàm thoại được thiết lập khi kết nối chính thức được tạo, kết nối này được duy trì và phải sử dụng một quá trình nào đó để ngắt nó. Khi nói về các session, lý thuyết có đôi chút lộn xộn, chính vì vậy chúng ta hãy xem xét một session theo một cảm nhận thực tế hơn.
Địa chỉ IP và địa chỉ MAC là gì???
Nếu bạn muốn gửi một lá thư, bạn cần địa chỉ của người nhận. Địa chỉ là đặc điểm nhận dạng giúp bưu tá biết bức thư cần được gửi đến đâu, vì vậy địa chỉ phải là duy nhất. Hai ngôi nhà không thể có cùng một địa chỉ, nếu không thì sẽ có sự nhầm lẫn.
Internet hoạt động theo cách tương tự như dịch vụ bưu chính. Thay vì gửi thư, các thiết bị gửi “gói dữ liệu”, và địa chỉ IP hay địa chỉ MAC xác định nơi các gói dữ liệu đó sẽ đến. Bài viết hôm nay sẽ nói về cách hai địa chỉ này hoạt động song song với nhau.
Địa chỉ MAC là gì?
Một địa chỉ MAC xác định một "giao diện mạng" duy nhất trong một thiết bị. Trong khi địa chỉ IP được chỉ định bởi ISP và có thể được gán lại khi thiết bị kết nối hoặc ngắt kết nối, địa chỉ MAC được gắn với adapter (bộ điều hợp) vật lý và được chỉ định bởi nhà sản xuất.
Địa chỉ MAC là một chuỗi gồm 12 chữ số, trong đó mỗi chữ số có thể là bất kỳ số nào từ 0 đến 9 hoặc chữ cái từ A đến F. Để dễ đọc, chuỗi được chia thành các khối. Có ba định dạng phổ biến, định dạng đầu tiên là cái phổ biến và được ưa thích nhất:
68:7F:74:12:34:56
68-7F-74-12-34-56
687.F74.123.456
6 chữ số đầu tiên (được gọi là “tiền tố”) đại diện cho nhà sản xuất adapter, còn 6 chữ số cuối đại diện cho số nhận dạng duy nhất cho adapter cụ thể đó. Địa chỉ MAC không chứa thông tin về việc thiết bị được kết nối với mạng nào.
Địa chỉ IP và địa chỉ MAC hoạt động song song như thế nào?
Địa chỉ IP được sử dụng để truyền dữ liệu từ mạng này sang mạng khác bằng giao thức TCP/IP. Địa chỉ MAC được sử dụng để phân phối dữ liệu đến đúng thiết bị trên mạng.
Giả sử tên của bạn là “John Smith”. Chưa đủ để nhận dạng chính xác vì có rất nhiều người có cùng tên như vậy. Nhưng nếu ta kết hợp cùng tổ tiên của bạn (tức là “nhà sản xuất”) thì sao? Bạn sẽ là "John Smith, con trai của Edward, Edward là con trai của George, George là con trai của ..." Tất cả các thông tin này mới đủ để biến cái tên “John Smith” trở thành duy nhất. Đó chính là địa chỉ MAC của bạn.
Nếu ai đó muốn gửi một gói bưu phẩm cho bạn, người đó không thể nói với bưu điện rằng hãy gửi nó đến cho "John Smith, con trai của Edward, Edward là con trai của George, George là con trai của ..." được. Mặc dù nó xác định chính xác người nhận là bạn, nhưng nó sẽ khiến bưu điện phát điên nếu phải tìm bạn. Đó là lý do tại sao cần có địa chỉ nhà.
Nhưng bản thân địa chỉ nhà thôi cũng không đủ. Cần cả địa chỉ nhà và tên của bạn, nếu không bạn sẽ nhận được gói hàng nhưng không biết nó gửi cho bạn, vợ hay con của bạn, v.v... Địa chỉ IP là nơi bạn đang ở, còn địa chỉ MAC cho biết bạn là ai.
Điều này sẽ như thế nào trong thực tế?
Router/modem của bạn có một địa chỉ IP duy nhất (địa chỉ nhà) được chỉ định bởi ISP của bạn (dịch vụ bưu chính). Các thiết bị kết nối với router/modem đó (người sống trong ngôi nhà) có địa chỉ MAC duy nhất (tên cá nhân). Địa chỉ IP nhận dữ liệu đến router/modem (hộp thư), sau đó router/modem sẽ chuyển tiếp đến thiết bị phù hợp (người nhận).
Lợi ích của địa chỉ MAC
Đây là cách tính năng lọc của MAC hoạt động trên các router hiện đại: Bạn có thể yêu cầu router từ chối truy cập vào các địa chỉ MAC cụ thể (ví dụ, thiết bị vật lý cụ thể) hoặc chỉ cho phép một số địa chỉ MAC nhất định kết nối.
Bạn không thể làm tương tự với địa chỉ IP vì các router gán địa chỉ IP nội bộ cho các thiết bị khi chúng kết nối và “tái chế” chúng khi thiết bị ngắt kết nối. Đó là lý do tại sao điện thoại thông minh của bạn có thể có địa chỉ IP nội bộ là 192.168.0.1 vào buổi sáng nhưng lại thành 192.168.0.3 khi bạn đi làm về. Chặn “192.168.0.1” sẽ không có ý nghĩa gì cả.
Một cách sử dụng tiện lợi khác cho các địa chỉ MAC là kích hoạt Wake-on-LAN. Các adapter Ethernet có thể chấp nhận một “gói ma thuật” làm cho thiết bị “thức”, ngay cả khi nó đã được tắt. Gói ma thuật này có thể được gửi từ bất cứ đâu trên cùng một mạng, và địa chỉ MAC của adapter Ethernet thiết bị nhận là cách gói ma thuật biết sẽ phải đi đâu.
Điểm yếu của địa chỉ IP và địa chỉ MAC
Bạn còn nhớ làm thế nào một địa chỉ IP biểu thị kết nối của một thiết bị với một ISP không? Điều gì sẽ xảy ra nếu thiết bị thứ hai kết nối với thiết bị và kênh chính trong tất cả hoạt động web thông qua thiết bị đó? Đối với phần còn lại của web, hoạt động của thiết bị thứ hai có vẻ như là thiết bị chính.
Đó là cách bạn ẩn địa chỉ IP của mình với những người khác. Mặc dù không có gì sai khi thực hiện việc này nhưng nó có thể dẫn đến các vấn đề về bảo mật. Ví dụ, một hacker độc hại, ẩn đằng sau một số proxy có thể làm cho các nhà chức trách rất khó để theo dõi anh ta.
Một nguy cơ nữa là các địa chỉ IP có thể bị truy tìm. Bạn sẽ ngạc nhiên về những gì ai đó có thể làm chỉ với địa chỉ IP của bạn.
Và đó cũng là vấn đề tiềm ẩn của xung đột IP, trong đó hai hoặc nhiều thiết bị chia sẻ cùng một địa chỉ IP. Điều này chủ yếu xảy ra trong một mạng nội bộ, nhưng với sự thiếu hụt địa chỉ IPv4 ngày càng tăng, nó có thể sớm lan tràn trên toàn bộ mạng Internet.
Đối với địa chỉ MAC, thực sự chỉ có một vấn đề bạn cần biết: Rất dễ dàng thay đổi địa chỉ MAC của thiết bị. Việc này làm mất đi mục đích của mã định danh duy nhất do nhà sản xuất chỉ định, vì bất kỳ ai cũng có thể “giả mạo” địa chỉ MAC của một người khác. Nó cũng làm cho các tính năng như bộ lọc MAC gần như vô dụng.
Bất kể địa chỉ IP và địa chỉ MAC nào cũng đều hữu ích và quan trọng, vì vậy chúng sẽ không sớm biến mất. Hy vọng rằng bây giờ bạn đã hiểu chúng là gì, chúng hoạt động ra sao và tại sao bạn cần chúng.
Internet hoạt động theo cách tương tự như dịch vụ bưu chính. Thay vì gửi thư, các thiết bị gửi “gói dữ liệu”, và địa chỉ IP hay địa chỉ MAC xác định nơi các gói dữ liệu đó sẽ đến. Bài viết hôm nay sẽ nói về cách hai địa chỉ này hoạt động song song với nhau.
Địa chỉ MAC là gì?
Một địa chỉ MAC xác định một "giao diện mạng" duy nhất trong một thiết bị. Trong khi địa chỉ IP được chỉ định bởi ISP và có thể được gán lại khi thiết bị kết nối hoặc ngắt kết nối, địa chỉ MAC được gắn với adapter (bộ điều hợp) vật lý và được chỉ định bởi nhà sản xuất.
Địa chỉ MAC là một chuỗi gồm 12 chữ số, trong đó mỗi chữ số có thể là bất kỳ số nào từ 0 đến 9 hoặc chữ cái từ A đến F. Để dễ đọc, chuỗi được chia thành các khối. Có ba định dạng phổ biến, định dạng đầu tiên là cái phổ biến và được ưa thích nhất:
68:7F:74:12:34:56
68-7F-74-12-34-56
687.F74.123.456
6 chữ số đầu tiên (được gọi là “tiền tố”) đại diện cho nhà sản xuất adapter, còn 6 chữ số cuối đại diện cho số nhận dạng duy nhất cho adapter cụ thể đó. Địa chỉ MAC không chứa thông tin về việc thiết bị được kết nối với mạng nào.
Địa chỉ IP và địa chỉ MAC hoạt động song song như thế nào?
Địa chỉ IP được sử dụng để truyền dữ liệu từ mạng này sang mạng khác bằng giao thức TCP/IP. Địa chỉ MAC được sử dụng để phân phối dữ liệu đến đúng thiết bị trên mạng.
Giả sử tên của bạn là “John Smith”. Chưa đủ để nhận dạng chính xác vì có rất nhiều người có cùng tên như vậy. Nhưng nếu ta kết hợp cùng tổ tiên của bạn (tức là “nhà sản xuất”) thì sao? Bạn sẽ là "John Smith, con trai của Edward, Edward là con trai của George, George là con trai của ..." Tất cả các thông tin này mới đủ để biến cái tên “John Smith” trở thành duy nhất. Đó chính là địa chỉ MAC của bạn.
Nếu ai đó muốn gửi một gói bưu phẩm cho bạn, người đó không thể nói với bưu điện rằng hãy gửi nó đến cho "John Smith, con trai của Edward, Edward là con trai của George, George là con trai của ..." được. Mặc dù nó xác định chính xác người nhận là bạn, nhưng nó sẽ khiến bưu điện phát điên nếu phải tìm bạn. Đó là lý do tại sao cần có địa chỉ nhà.
Nhưng bản thân địa chỉ nhà thôi cũng không đủ. Cần cả địa chỉ nhà và tên của bạn, nếu không bạn sẽ nhận được gói hàng nhưng không biết nó gửi cho bạn, vợ hay con của bạn, v.v... Địa chỉ IP là nơi bạn đang ở, còn địa chỉ MAC cho biết bạn là ai.
Điều này sẽ như thế nào trong thực tế?
Router/modem của bạn có một địa chỉ IP duy nhất (địa chỉ nhà) được chỉ định bởi ISP của bạn (dịch vụ bưu chính). Các thiết bị kết nối với router/modem đó (người sống trong ngôi nhà) có địa chỉ MAC duy nhất (tên cá nhân). Địa chỉ IP nhận dữ liệu đến router/modem (hộp thư), sau đó router/modem sẽ chuyển tiếp đến thiết bị phù hợp (người nhận).
Lợi ích của địa chỉ MAC
Đây là cách tính năng lọc của MAC hoạt động trên các router hiện đại: Bạn có thể yêu cầu router từ chối truy cập vào các địa chỉ MAC cụ thể (ví dụ, thiết bị vật lý cụ thể) hoặc chỉ cho phép một số địa chỉ MAC nhất định kết nối.
Bạn không thể làm tương tự với địa chỉ IP vì các router gán địa chỉ IP nội bộ cho các thiết bị khi chúng kết nối và “tái chế” chúng khi thiết bị ngắt kết nối. Đó là lý do tại sao điện thoại thông minh của bạn có thể có địa chỉ IP nội bộ là 192.168.0.1 vào buổi sáng nhưng lại thành 192.168.0.3 khi bạn đi làm về. Chặn “192.168.0.1” sẽ không có ý nghĩa gì cả.
Một cách sử dụng tiện lợi khác cho các địa chỉ MAC là kích hoạt Wake-on-LAN. Các adapter Ethernet có thể chấp nhận một “gói ma thuật” làm cho thiết bị “thức”, ngay cả khi nó đã được tắt. Gói ma thuật này có thể được gửi từ bất cứ đâu trên cùng một mạng, và địa chỉ MAC của adapter Ethernet thiết bị nhận là cách gói ma thuật biết sẽ phải đi đâu.
Điểm yếu của địa chỉ IP và địa chỉ MAC
Bạn còn nhớ làm thế nào một địa chỉ IP biểu thị kết nối của một thiết bị với một ISP không? Điều gì sẽ xảy ra nếu thiết bị thứ hai kết nối với thiết bị và kênh chính trong tất cả hoạt động web thông qua thiết bị đó? Đối với phần còn lại của web, hoạt động của thiết bị thứ hai có vẻ như là thiết bị chính.
Đó là cách bạn ẩn địa chỉ IP của mình với những người khác. Mặc dù không có gì sai khi thực hiện việc này nhưng nó có thể dẫn đến các vấn đề về bảo mật. Ví dụ, một hacker độc hại, ẩn đằng sau một số proxy có thể làm cho các nhà chức trách rất khó để theo dõi anh ta.
Một nguy cơ nữa là các địa chỉ IP có thể bị truy tìm. Bạn sẽ ngạc nhiên về những gì ai đó có thể làm chỉ với địa chỉ IP của bạn.
Và đó cũng là vấn đề tiềm ẩn của xung đột IP, trong đó hai hoặc nhiều thiết bị chia sẻ cùng một địa chỉ IP. Điều này chủ yếu xảy ra trong một mạng nội bộ, nhưng với sự thiếu hụt địa chỉ IPv4 ngày càng tăng, nó có thể sớm lan tràn trên toàn bộ mạng Internet.
Đối với địa chỉ MAC, thực sự chỉ có một vấn đề bạn cần biết: Rất dễ dàng thay đổi địa chỉ MAC của thiết bị. Việc này làm mất đi mục đích của mã định danh duy nhất do nhà sản xuất chỉ định, vì bất kỳ ai cũng có thể “giả mạo” địa chỉ MAC của một người khác. Nó cũng làm cho các tính năng như bộ lọc MAC gần như vô dụng.
Bất kể địa chỉ IP và địa chỉ MAC nào cũng đều hữu ích và quan trọng, vì vậy chúng sẽ không sớm biến mất. Hy vọng rằng bây giờ bạn đã hiểu chúng là gì, chúng hoạt động ra sao và tại sao bạn cần chúng.
Thủ thuật giúp bạn khắc phục lỗi Full Disk 100% trên Windows
Hướng dẫn fix lỗi 100% disk :
1. Set Ram ảo bằng thủ công thay vì để chế độ Automatically
2. Xử lý Troubleshooting
3. Tắt Maintenance
4. Tắt Windows SmartScreen
5. Tắt Service Superfetch
6. Tắt Service Windows Search
7. Tắt Disk Diagnostics: Configure execution level
8. Chống phân mảnh ổ cứng
9. Sử dụng các phần mềm dọn rác và sửa lỗi Registry
1. Set Ram ảo bằng thủ công thay vì để chế độ Automatically
Để Ram ở chế độ Automatically (tự động) cũng là một trong những nguyên nhân khiến máy tính bạn bị dính lỗi Full Disk. Thay vì để chế độ Auto thì bạn nên Set cứng RAM ảo. Cách thực hiện như ảnh ở dưới:
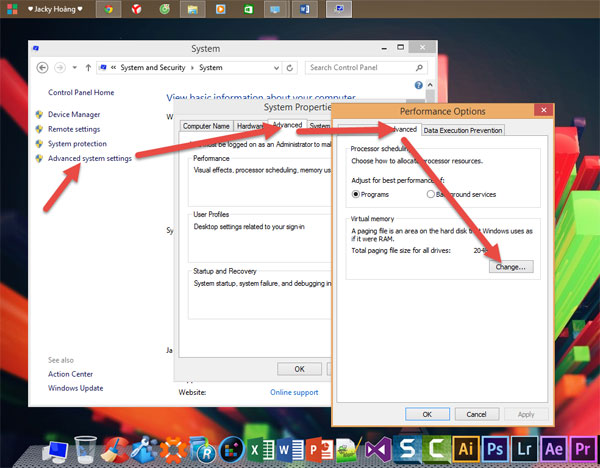
Tại Tab Virtual Memory, bỏ dấu tick ở Automatically manage paging file size for all drives. Chọn ổ đĩa cài Hệ điều hành của bạn (thường là ổ C). Sau đó tích vào Custom size.
Tại mục Maximum size và Initial size. Bạn set cứng cho Ram ảo bằng 1/2 Ram thật của bạn. Ở đây mình có 4GB Ram nên sẽ Set một nửa là 2GB Ram = 2048MB, tương tự các bạn làm với máy tính của bạn.
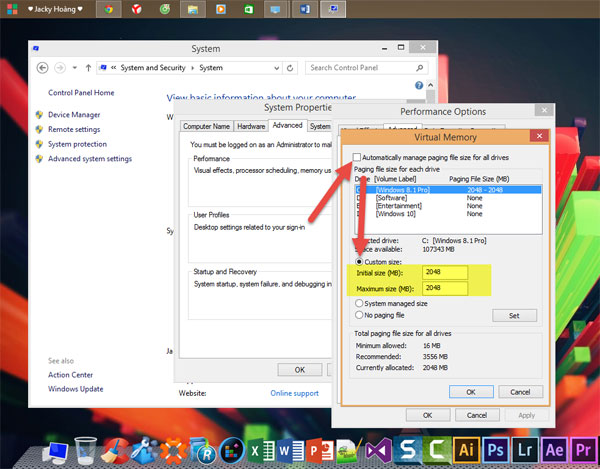
Cuối cùng ấn OK để lưu, và khởi động để thay đổi có hiệu lực.
2. Xử lý Troubleshooting
Bạn vào Control Panel, gõ Troubleshooting trên ô tìm kiếm và nhấn vào Troubleshooting.
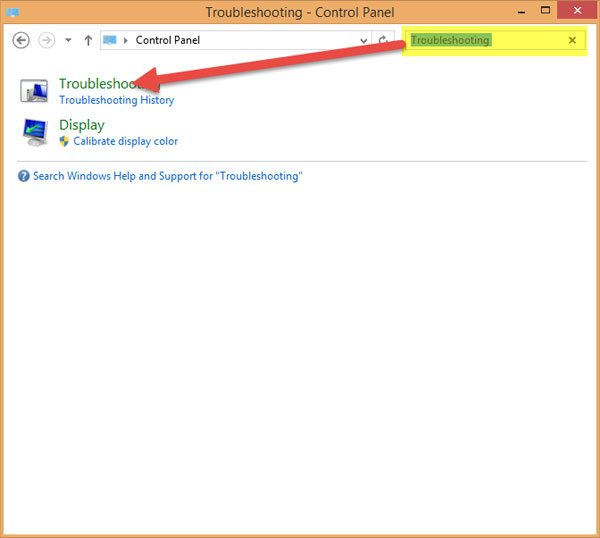
Cửa sổ mới hiện ra, kích đúp chuột vào System and Security:
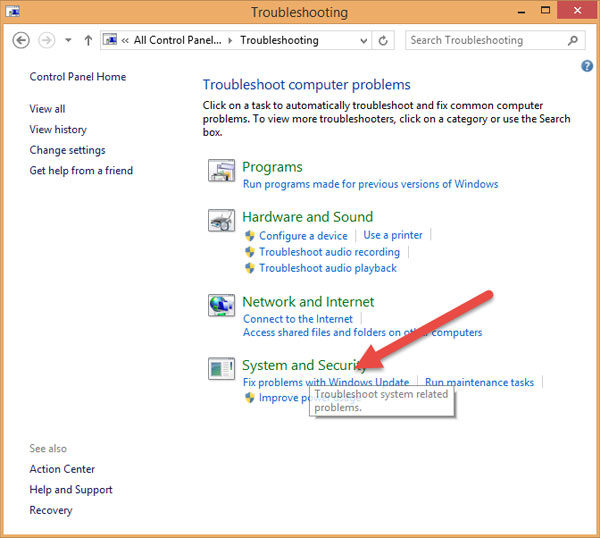
Cửa sổ mới hiện ra, kích vào System Maintenance:
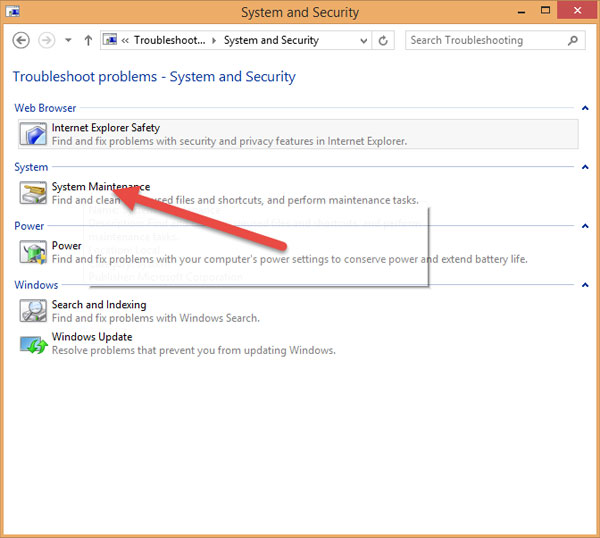
Nhấn Next:
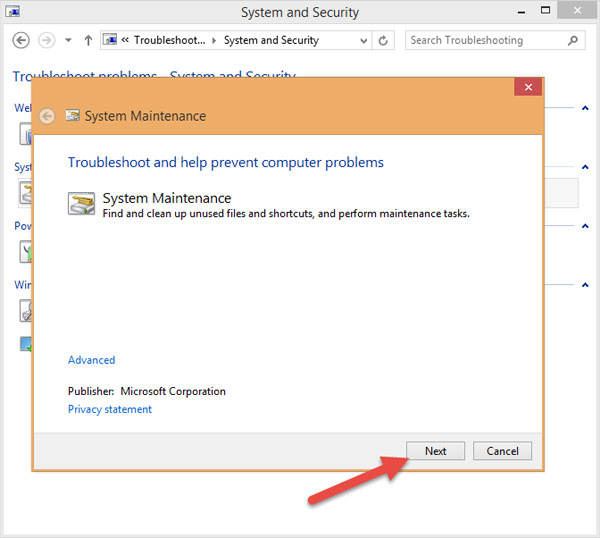
Sau đó cứ để cho máy nó làm việc khi xuất hiện thông báo System Maintenance như hình thì nhấn vào mục Try troubleshooting as an administrator:
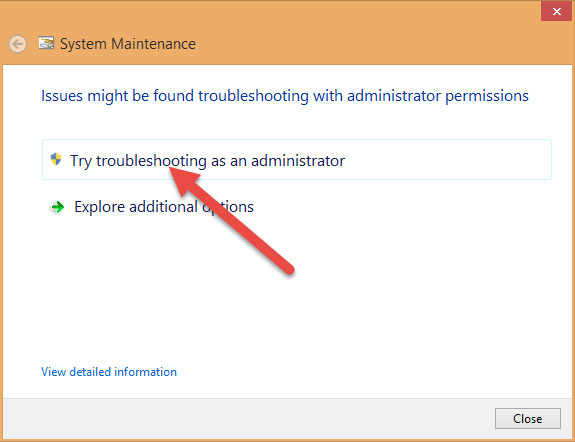
Sau đó ngồi đợi, chờ cho nó chạy đến khi nào có chữ Close thì nhấn vào.
Bạn vào Control Panel, gõ Troubleshooting trên ô tìm kiếm và nhấn vào Troubleshooting.
Cửa sổ mới hiện ra, kích đúp chuột vào System and Security:
Cửa sổ mới hiện ra, kích vào System Maintenance:
Nhấn Next:
Sau đó cứ để cho máy nó làm việc khi xuất hiện thông báo System Maintenance như hình thì nhấn vào mục Try troubleshooting as an administrator:
Sau đó ngồi đợi, chờ cho nó chạy đến khi nào có chữ Close thì nhấn vào.
3. Tắt Maintenance
Cũng ở Control Panel, chọn System and Security và Action Center:
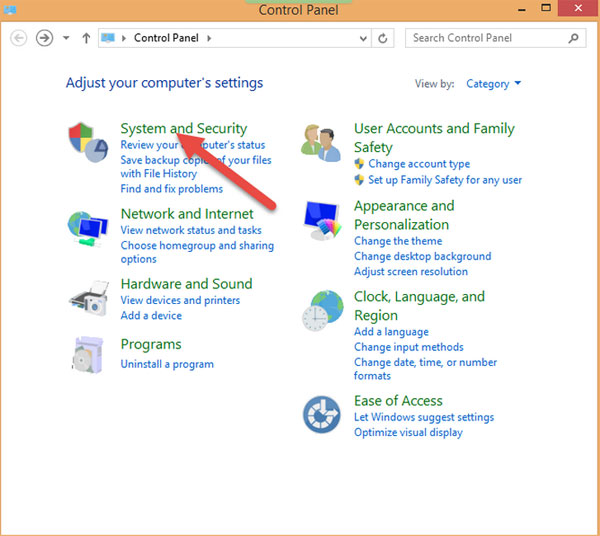
Tiếp theo nhấp chuột vào mũi tên đở phần thiết lập Maintenance, chọn Settings:
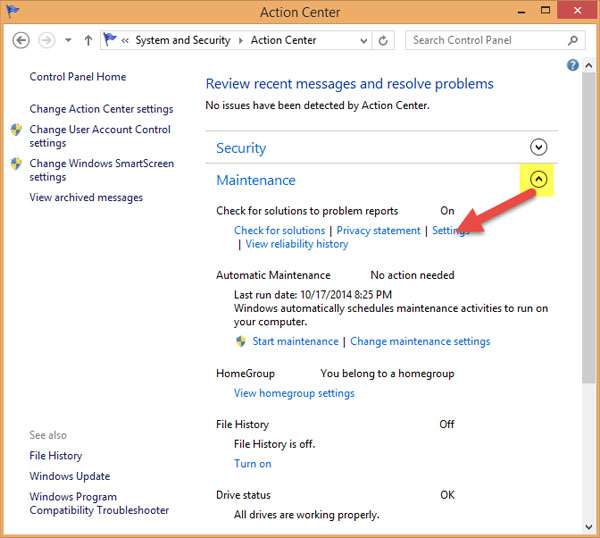
Bạn tích vào Never check for solutions (Not recommended) và OK:
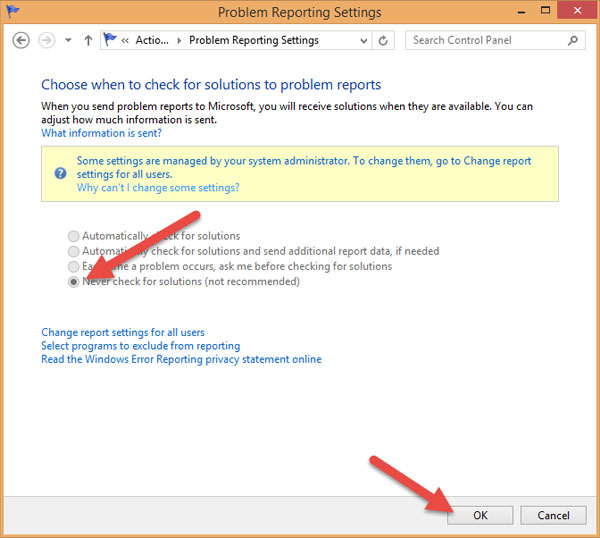
4. Tắt Windows SmartScreen
Vẫn ở cửa sổ Action Center, chọn Change Windows SmartScreen Settings, sau đó tích vào Don’t do anything (Turn off Windows SmartScreen).
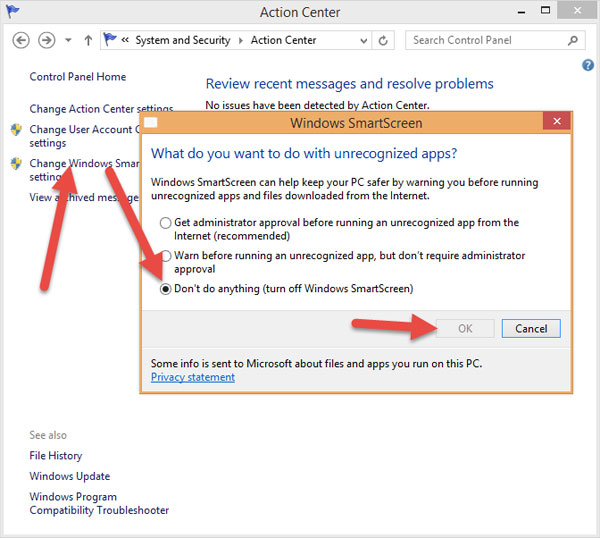
Vẫn ở cửa sổ Action Center, chọn Change Windows SmartScreen Settings, sau đó tích vào Don’t do anything (Turn off Windows SmartScreen).
5. Tắt Service Superfetch
Các bạn ấn tổ hợp phím Windows + R để mở Run gõ Services.msc. Sau đó tìm Superfetch (ấn S rồi tìm cho nhanh), kích đúp vào nó và chọn Disabled.
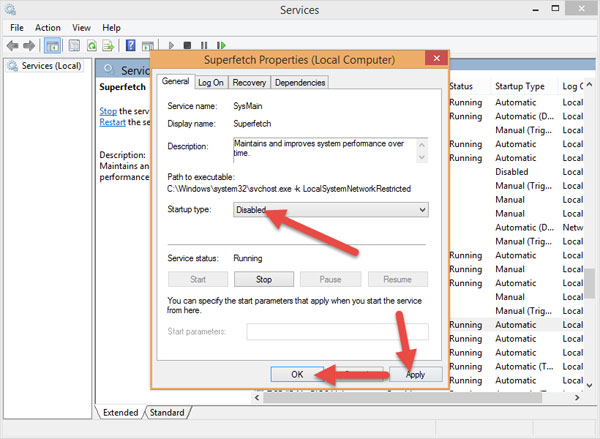
Các bạn ấn tổ hợp phím Windows + R để mở Run gõ Services.msc. Sau đó tìm Superfetch (ấn S rồi tìm cho nhanh), kích đúp vào nó và chọn Disabled.
6. Tắt Service Windows Search
Các bạn cũng làm tương tự như trên nhưng tìm Windows Search (ấn W rồi tìm), kích đúp vào nó và chọn Disabled.
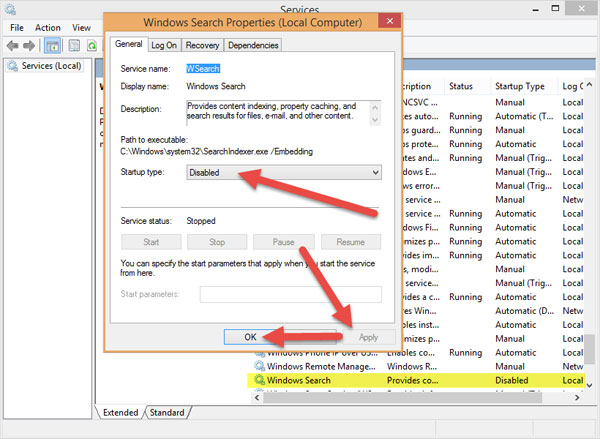
7. Tắt Disk Diagnostics: Configure execution level
Các bạn vào Run gõ gpedit.msc. Sau đó tìm đến đường dẫn sau:
Computer Configuration / Adminnistrative Templates / System / Troubleshooting and Diagnostics / Disk Diagnostics
Nhìn sang cửa sổ bên phải bạn sẽ thấy Disk Diagnostics: Configure execution level, kích đúp vào nó.
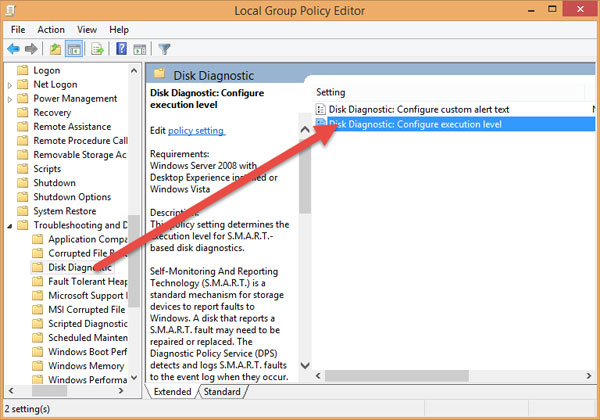
Chọn Disabled và OK để lưu.
Các bạn cũng làm tương tự như trên nhưng tìm Windows Search (ấn W rồi tìm), kích đúp vào nó và chọn Disabled.
7. Tắt Disk Diagnostics: Configure execution level
Các bạn vào Run gõ gpedit.msc. Sau đó tìm đến đường dẫn sau:
Computer Configuration / Adminnistrative Templates / System / Troubleshooting and Diagnostics / Disk Diagnostics
Nhìn sang cửa sổ bên phải bạn sẽ thấy Disk Diagnostics: Configure execution level, kích đúp vào nó.
Chọn Disabled và OK để lưu.
8. Chống phân mảnh ổ cứng
Hiện nay có rất nhiều phần mềm để chống phân mảnh ổ cứng nhưng trong bài này mình sẽ sử dụng công cụ của Windows.
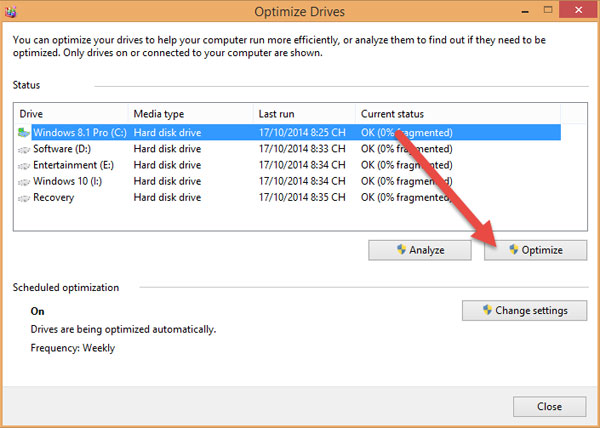
Mở This PC. Sau đó bạn nhấp vào một phân vùng bất kỳ, rồi chọn Manage -> Optimize.
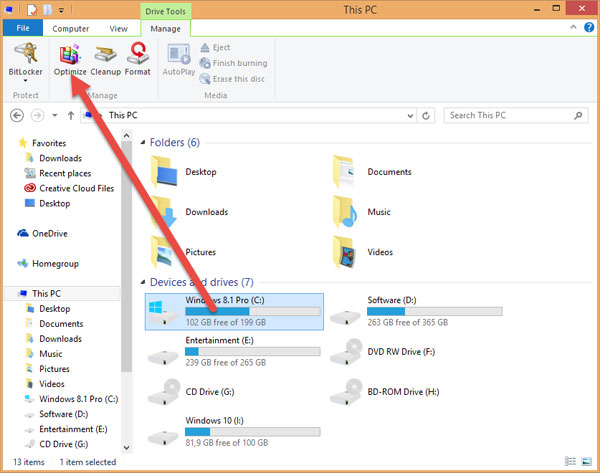
Chọn phân vùng mà bạn muốn chống phân mảnh (nên chọn ổ cài ổ chứa HDH trước) rồi nhấn vào Optimize để tiến hành chống phân mảnh và tối ưu hóa phân vùng.
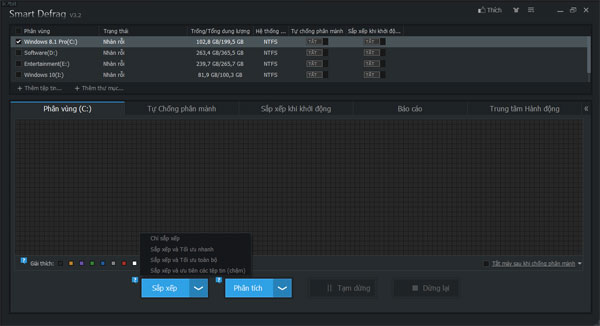
Ngoài ra, các bạn có thể sử dụng phần mềm bên thứ 3 như Smart Defrag 3, ưu điểm của phần mềm này là dễ sử dụng, hỗ trợ ngôn ngữ tiếng việt và hoàn toàn Miễn phí, các bạn có thể tải về và sử dụng tại:
Hiện nay có rất nhiều phần mềm để chống phân mảnh ổ cứng nhưng trong bài này mình sẽ sử dụng công cụ của Windows.
Mở This PC. Sau đó bạn nhấp vào một phân vùng bất kỳ, rồi chọn Manage -> Optimize.
Chọn phân vùng mà bạn muốn chống phân mảnh (nên chọn ổ cài ổ chứa HDH trước) rồi nhấn vào Optimize để tiến hành chống phân mảnh và tối ưu hóa phân vùng.
Ngoài ra, các bạn có thể sử dụng phần mềm bên thứ 3 như Smart Defrag 3, ưu điểm của phần mềm này là dễ sử dụng, hỗ trợ ngôn ngữ tiếng việt và hoàn toàn Miễn phí, các bạn có thể tải về và sử dụng tại:
9. Sử dụng các phần mềm dọn rác và sửa lỗi Registry
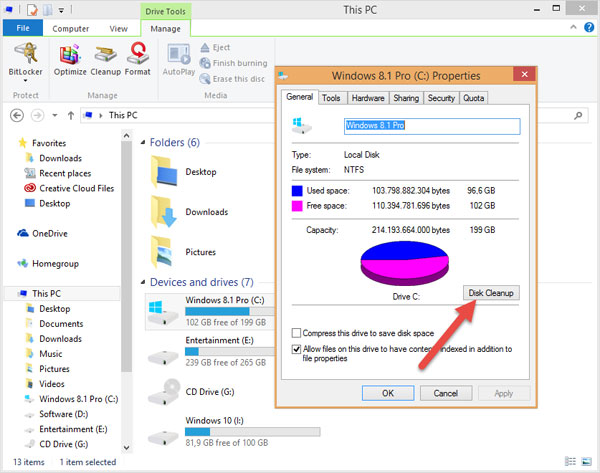
Mở This PC, sau đó bạn nhấp vào một phân vùng mà bạn cài hệ điều hành (thường là ổ C). Chuột phải > Properties > Disk Cleanup.
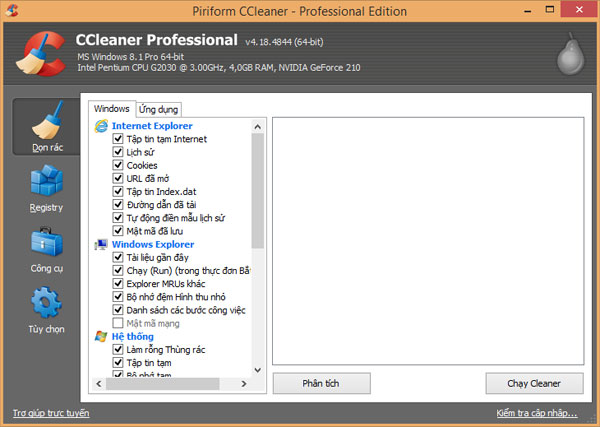
Nếu muốn nhanh hơn thì các bạn có thể dùng phần mềm CCleaner, các bạn tải tại đây:
Mở This PC, sau đó bạn nhấp vào một phân vùng mà bạn cài hệ điều hành (thường là ổ C). Chuột phải > Properties > Disk Cleanup.
Nếu muốn nhanh hơn thì các bạn có thể dùng phần mềm CCleaner, các bạn tải tại đây:
10. Gỡ các phần mềm không cần thiết, tắt các phần mềm không cần dùng lúc Windows khởi động
- Để gỡ các phần mềm không cần thiết các bạn có thể dùng chức năng có sẵn của Windows hoặc phần mềm bên thứ 3 như Revo Uninstaller, CCleaner,...
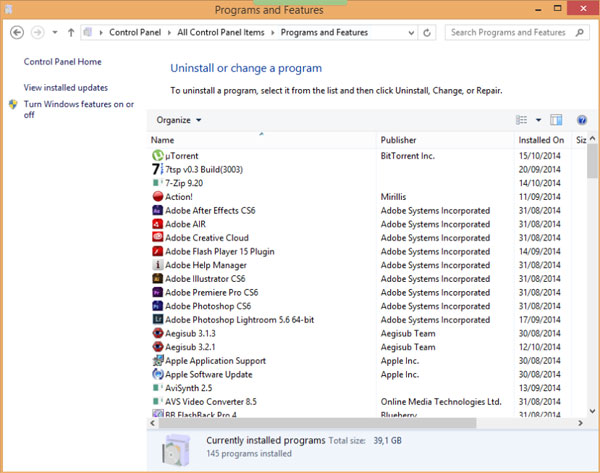
- Còn tắt các phần mềm, các bạn có thể sử dụng công cụ Startup ở thanh Task Manager, rồi Disable phần mềm mà bạn thấy không cần thiết (lưu ý không Disable Driver của hệ thống nhé).
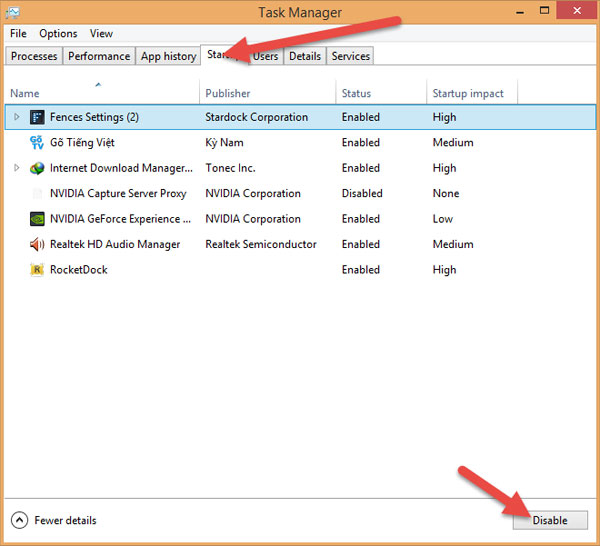
- Để gỡ các phần mềm không cần thiết các bạn có thể dùng chức năng có sẵn của Windows hoặc phần mềm bên thứ 3 như Revo Uninstaller, CCleaner,...
- Còn tắt các phần mềm, các bạn có thể sử dụng công cụ Startup ở thanh Task Manager, rồi Disable phần mềm mà bạn thấy không cần thiết (lưu ý không Disable Driver của hệ thống nhé).
11. Windows Update
Tải các bản vá lỗi của Mircosoft để sửa lỗi cho Windows của bạn.
Tải các bản vá lỗi của Mircosoft để sửa lỗi cho Windows của bạn.
12. Chạy CheckDisk
1. Click Start, sau đó nhập cmd vào khung Search. Trên danh sách kết quả tìm kiếm, kích chuột phải vào Command Prompt chọn Run as administrator.
2. Trên cửa sổ Command prompt, bạn nhập câu lệnh dưới đây vào để kiểm tra và tự động khắc phục các lỗi trên ổ đĩa cứng của bạn:
chkdsk /f' /r C:
Lưu ý: Trong câu lệnh trên, thay thế "C" bằng tên các ổ đĩa cứng chính trên máy tính Windows của bạn.
3. Lúc này trên màn hình bạn sẽ nhận được thông báo ổ đĩa cứng đang sử dụng, nếu muốn chạy CheckDisk khởi động lại hệ thống. Nhấn Y để khởi động lại máy tính của bạn.
4. CheckDisk sẽ chạy sau khi máy tính của bạn khởi động. Quá trình diễn ra sẽ khá lâu, do đó bạn cần phải kiên nhẫn. Quá trình kết thúc và lỗi sẽ không còn xuất hiện nữa.
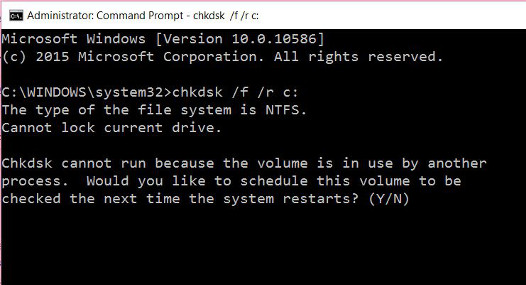
1. Click Start, sau đó nhập cmd vào khung Search. Trên danh sách kết quả tìm kiếm, kích chuột phải vào Command Prompt chọn Run as administrator.
2. Trên cửa sổ Command prompt, bạn nhập câu lệnh dưới đây vào để kiểm tra và tự động khắc phục các lỗi trên ổ đĩa cứng của bạn:
chkdsk /f' /r C:
Lưu ý: Trong câu lệnh trên, thay thế "C" bằng tên các ổ đĩa cứng chính trên máy tính Windows của bạn.
3. Lúc này trên màn hình bạn sẽ nhận được thông báo ổ đĩa cứng đang sử dụng, nếu muốn chạy CheckDisk khởi động lại hệ thống. Nhấn Y để khởi động lại máy tính của bạn.
4. CheckDisk sẽ chạy sau khi máy tính của bạn khởi động. Quá trình diễn ra sẽ khá lâu, do đó bạn cần phải kiên nhẫn. Quá trình kết thúc và lỗi sẽ không còn xuất hiện nữa.
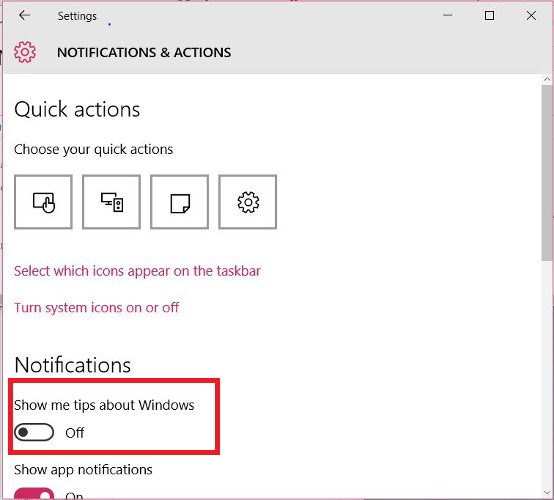
13. Vô hiệu hóa Tips About Windows
Đôi khi trong một số trường hợp, người dùng có thể vô hiệu hóa Tips About Windows để khắc phục lỗi.
Để vô hiệu hóa Tips About Windows, bạn vào Start => Settings => System => Notification & actions. Chuyển đổi tùy chọn Show me tips about Windows sang OFF là xong.
Đôi khi trong một số trường hợp, người dùng có thể vô hiệu hóa Tips About Windows để khắc phục lỗi.
Để vô hiệu hóa Tips About Windows, bạn vào Start => Settings => System => Notification & actions. Chuyển đổi tùy chọn Show me tips about Windows sang OFF là xong.
14. Thay đổi vị trí Pagefile
Pagefile là một file trên ổ đĩa cứng để hỗ trợ khả năng ghi có “hạn” của RAM trong máy tính trong trường hợp cần thiết.
Máy tính của bạn sẽ ưu tiên sử dụng RAM để lưu trữ dữ liệu bởi vì khả năng truy suất của nó nhanh hơn ổ cứng. Tuy nhiên, khi bộ nhớ RAM đầy hoặc quá tải thì Windows sẽ tự động chuyển các dữ liệu từ RAM sang Pagefile trong ổ cứng.
Tuy nhiên trong một số trường hợp nguyên nhân gây lỗi Disk Usage có thể là do Pagefile được sử dụng liên tục.
Để khắc phục lỗi, giải pháp đầu tiên bạn có thể áp dụng là cấy thêm RAM. Tuy nhiên để không phải mất tiền oan, bạn có thể áp dụng cách khác là di chuyển pagefile sang ổ không phải là ổ cứng hệ thống. Để làm được điều này:
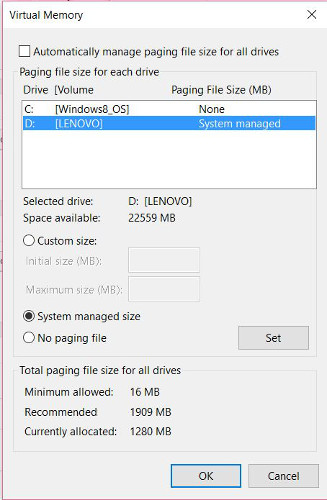
1. Kích chuột phải vào My Computer hoặc This PC, chọn Properties.
2. Tiếp theo vào Advanced system settings => Settings (dưới mục Performance) => Advanced => Change.
3. Theo mặc định pagefile sẽ được chọn, bạn chọn No paging file rồi click chọn Set.
4. Tiếp theo chọn ổ đĩa cứng mà bạn muốn di chuyển pagefile sang, sau đó click chọn “System managed size” => Set.
5. Click chọn OK và khởi động lại máy tính của bạn.
Pagefile là một file trên ổ đĩa cứng để hỗ trợ khả năng ghi có “hạn” của RAM trong máy tính trong trường hợp cần thiết.
Máy tính của bạn sẽ ưu tiên sử dụng RAM để lưu trữ dữ liệu bởi vì khả năng truy suất của nó nhanh hơn ổ cứng. Tuy nhiên, khi bộ nhớ RAM đầy hoặc quá tải thì Windows sẽ tự động chuyển các dữ liệu từ RAM sang Pagefile trong ổ cứng.
Tuy nhiên trong một số trường hợp nguyên nhân gây lỗi Disk Usage có thể là do Pagefile được sử dụng liên tục.
Để khắc phục lỗi, giải pháp đầu tiên bạn có thể áp dụng là cấy thêm RAM. Tuy nhiên để không phải mất tiền oan, bạn có thể áp dụng cách khác là di chuyển pagefile sang ổ không phải là ổ cứng hệ thống. Để làm được điều này:
1. Kích chuột phải vào My Computer hoặc This PC, chọn Properties.
2. Tiếp theo vào Advanced system settings => Settings (dưới mục Performance) => Advanced => Change.
3. Theo mặc định pagefile sẽ được chọn, bạn chọn No paging file rồi click chọn Set.
4. Tiếp theo chọn ổ đĩa cứng mà bạn muốn di chuyển pagefile sang, sau đó click chọn “System managed size” => Set.
5. Click chọn OK và khởi động lại máy tính của bạn.
Thứ Bảy, 22 tháng 12, 2018
THỦ THUẬT - TIPS Excel hay nhất mọi thời đại.
A
B
Back Ground
Page Layout => Back Ground
C
Chuyển đổi giữa các Tab Excel
Ctrl + Tab
Copy nhiều Cell
Shift để chọn n Cell,… Ctrl + C => Ctrl + V
D
Đổi size nhiều Col,Row cùng lúc
Home => Format => Row Heigh/ Colum Width
E
F
Fillter,Lọc
Click chọn Row or Colum
Home -> Filter
Freeze colum/Row
Để cố định Colum/Row khi Scroll chuột.
H
Hide Tool Bar
Ctrl + F1
I
Insert nhiều Cell cùng lúc…
Shift để chọn n cell cần Insert => Right Click => Insert
Cell
Insert File Text

K
Không cho sửa File
Review-> Protect Sheet
M
Merger cells
Home => Merger
R
Remove Duplicate
Data => Remove Duplicate
T
Tràn chữ sang cell bên cạnh
Gõ 1 symbol… Eg “space”
S
Sắp xếp theo thứ tự:
Home -> Sort
Nhiều phiên bản là View -> Sort
Sửa tên Sheet
Double click to Sheet name
X
Xuống dòng trong 1 cell
Alt + Enter
Thứ Bảy, 27 tháng 10, 2018
Thủ thuật giúp bạn khắc phục lỗi Full Disk 100% trên Windows
1. Set Ram ảo bằng thủ công thay vì để chế độ Automatically
Để Ram ở chế độ Automatically (tự động) cũng là một trong những nguyên nhân khiến máy tính bạn bị dính lỗi Full Disk. Thay vì để chế độ Auto thì bạn nên Set cứng RAM ảo. Cách thực hiện như ảnh ở dưới:
Tại Tab Virtual Memory, bỏ dấu tick ở Automatically manage paging file size for all drives. Chọn ổ đĩa cài Hệ điều hành của bạn (thường là ổ C). Sau đó tích vào Custom size.
Tại mục Maximum size và Initial size. Bạn set cứng cho Ram ảo bằng 1/2 Ram thật của bạn. Ở đây mình có 4GB Ram nên sẽ Set một nửa là 2GB Ram = 2048MB, tương tự các bạn làm với máy tính của bạn.
Cuối cùng ấn OK để lưu, và khởi động để thay đổi có hiệu lực.
Để Ram ở chế độ Automatically (tự động) cũng là một trong những nguyên nhân khiến máy tính bạn bị dính lỗi Full Disk. Thay vì để chế độ Auto thì bạn nên Set cứng RAM ảo. Cách thực hiện như ảnh ở dưới:
Tại Tab Virtual Memory, bỏ dấu tick ở Automatically manage paging file size for all drives. Chọn ổ đĩa cài Hệ điều hành của bạn (thường là ổ C). Sau đó tích vào Custom size.
Tại mục Maximum size và Initial size. Bạn set cứng cho Ram ảo bằng 1/2 Ram thật của bạn. Ở đây mình có 4GB Ram nên sẽ Set một nửa là 2GB Ram = 2048MB, tương tự các bạn làm với máy tính của bạn.
Cuối cùng ấn OK để lưu, và khởi động để thay đổi có hiệu lực.
NTP Server là gì ? Tổng quan về dịch vụ NTP (Network Time Protocol) đồng bộ thời gian
NTP Server là gì ? Tổng quan về dịch vụ NTP (Network Time Protocol) đồng bộ thời gian | Để hiểu NTP là gì trước hết bạn cần phải hiểu đồng bộ thời gian quan trọng như thế nào. Đồng bộ thời gian là điều cần thiết cho các mạng máy tính hoặc dịch vụ Internet, đặc biệt là các mạng cần thời gian chính xác cho giao dịch. Thời gian ở đây, dưới dạng tem thời gian (timestamp), được sử dụng trên máy chủ cho nhiều mục đích như để xác định khi nào giao dịch đã diễn ra hoặc cần diễn ra. Do vậy, nếu thời gian khác, mọi thứ có thể sai lệch, giao dịch không được tiến hành hoặc dữ liệu sẽ bị mất.
Bạn đã thấy một nhu cầu tầm quan trọng của thời gian trên máy chủ rồi chứ? Do vậy
cần phải có một time server system (tạm dịch là hệ thống máy chủ thời gian) để
không chỉ giữ cho các thiết bị trên mạng chạy đồng thời một thời gian và còn đảm
bảo rằng các thiết bị mạng khác nhau giao tiếp với nhau cũng đồng bộ
1. NTP là gì?
NTP là gì ? Network Time Protocol (NTP) là một thuật toán phần mềm giữ cho các máy tính và các thiết bị công nghệ khác nhau có thể đồng bộ hóa thời gian với nhau.NTP đã đạt được thành công trong việc giữ các thiết bị đồng bộ hóa hiệu quả trong chỉ trong vài milliseconds (1/1000s), nhưng để có thể làm được điều này nó cần phải có một hệ thống thời gian đáng tin cậy để sử dụng làm điểm thời gian chính cho việc đồng bộ.
Bạn đã thấy một nhu cầu tầm quan trọng của thời gian trên máy chủ rồi chứ? Do vậy
cần phải có một time server system (tạm dịch là hệ thống máy chủ thời gian) để
không chỉ giữ cho các thiết bị trên mạng chạy đồng thời một thời gian và còn đảm
bảo rằng các thiết bị mạng khác nhau giao tiếp với nhau cũng đồng bộ
1. NTP là gì?
NTP là gì ? Network Time Protocol (NTP) là một thuật toán phần mềm giữ cho các máy tính và các thiết bị công nghệ khác nhau có thể đồng bộ hóa thời gian với nhau.NTP đã đạt được thành công trong việc giữ các thiết bị đồng bộ hóa hiệu quả trong chỉ trong vài milliseconds (1/1000s), nhưng để có thể làm được điều này nó cần phải có một hệ thống thời gian đáng tin cậy để sử dụng làm điểm thời gian chính cho việc đồng bộ.
2 cách để copy nội dung trên web không cho copy
Hiện nay, tình trạng copy nội dung bài viết từ website này sang website khác ngày càng nhiều. Chính vì thế, các Webmaster (người làm Web) đã sử dụng các đoạn JavaScript để khóa tính năng chuột trái hoặc phải trên trình duyệt.
Vậy để copy nội dung trên web đã bị khóa chuột, các bạn cần mở khóa chuột bằng cách tắt tính năng hỗ trợ JavaScript của trình duyệt là bạn có thể thao tác chuột để copy nội dung một cách bình thường. Ngoài ra, bạn có thể sử dụng thêm add-on hoặc dùng tính năng kiểm tra phần tử trang web thông qua phím F12. Dưới đây, Quantrimang.com sẽ hướng dẫn bạn cả cách tắt tính năng hỗ trợ JavaScript trên Google Chrome, Mozilla Firefox, cài add-on, sử dụng phím F12, mời các bạn cùng theo dõi nhé.
Copy nội dung website trên Chrome, Cốc Cốc
1. Cài add-on All Copy cho Chrome
Tải Enable Copy: https://chrome.google.com/webstore/detail/enable-copy/lmnganadkecefnhncokdlaohlkneihio
Cài Enable Copy cho Chrome
Truy cập trang web không cho phép sao chép nội dung
Nếu biểu tượng của add-on chưa chuyển sang màu đen, bạn click chuột vào biểu tượng của Enable Copy trên trình duyệt (đây là bước bắt buộc phải làm, để kích hoạt add-on)
Rồi, thích copy cái gì thì bạn copy thôi, có thể bôi đen, Ctrl + C hoặc bôi đen, chuột phải > Copy, đều OK nhé.
Cách này mình đã thử với một số trang và trang web của một bạn đọc comment bên dưới bài viết, đều OK.
2. Dùng allowcopy.com
Nếu ngại cài add-on lên trình duyệt bạn có thể truy cập vào trang web allowcopy.com, sau đó copy và dán link của trang web có nội dung bạn muốn copy vào khung URL > nhấn Submit. Allowcopy sẽ mở ra một trang mới với nội dung của trang web bạn dán vào, nhưng có thể copy như bình thường. Khá nhanh gọn và tiện lợi. Bạn thử xem nhé!
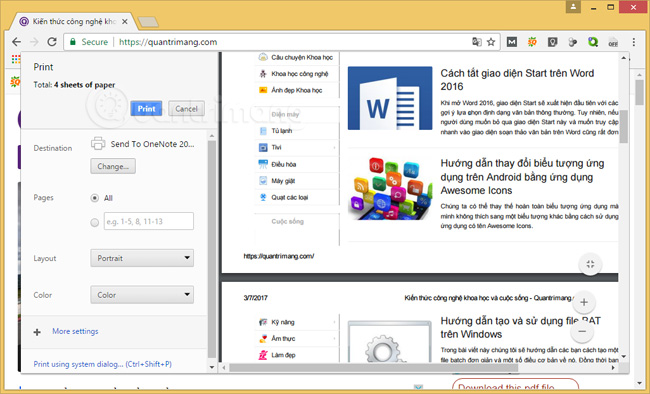
3. Sử dụng tính năng in để copy nội dung website:
Cảm ơn sự đóng góp của bạn đọc có Facebook là Kiên Đinh và Bo Cong đã giúp bài viết hoàn thiện hơn!
Tiếc là cách này chỉ áp dụng được trên trình duyệt Chrome, mình đã thử trên Firefox, Internet Explorer nhưng không sao chép được.
Để thực hiện, bạn chỉ cần mở trang web muốn copy, nhấn Ctrl + P hoặc dấu 3 chấm dọc ở góc trên bên phải, chọn Print. Trình duyệt sẽ cho phép xem trước trang web muốn in, bây giờ, bạn chỉ cần chọn đoạn muốn sao chép, bôi đen, Ctrl + C, rồi dán vào chỗ cần là xong.
4. Tắt tính năng hỗ trợ JavaScript trên Google Chrome
Nếu bạn ngại cài add-on trên trình duyệt thì có thể áp dụng cách tắt tính năng hỗ trợ JavaScript trên trình duyệt, tuy nhiên cách này chỉ dùng được khi trang web sử dụng đoạn mã Java để ngăn chặn sao chép, mặt khác, các mã Java khác cũng sẽ bị chặn, làm ảnh hưởng đến trải nghiệm duyệt web của bạn. Điều này có thể khắc phục bằng cách, chỉ tắt tính năng khi cần sao chép, sau khi copy xong thì lại bật lên.
Mở trình duyệt Google Chrome, nhấp vào dấu ⋮ ở góc bên trên bên phải > rồi chọn Cài đặt:
Các bạn chọn Hiển thị cài đặt nâng cao ở phía cuối.
Các bạn tìm đến phần Bảo mật và Riêng tư và chọn Cài đặt nội dung
Trong mục JavaScript các bạn gạt điều khiển ở bên phải để nó biến thành màu xám, chặn không cho các trang web chạy JavaScript là xong.
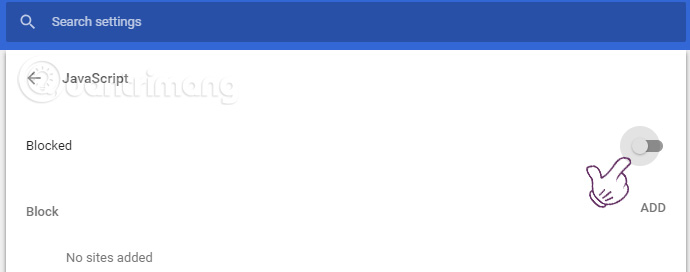
Trên các bản Chrome cũ hơn, bạn sẽ không thấy gạt điều khiển, thay vào đó là tùy chọn Không cho phép bất kỳ trang web nào chạy JavaScript, bạn hãy chọn tùy chọn này > Hoàn tất.
Lưu ý: Mình không khuyến khích làm cách này vì JavaScript là một phần không thể thiếu của các trang web, nếu bạn tắt đi sẽ khiến trang web không hiển thị được nhiều nội dung. Vì thế sau khi copy được nội dung bạn cần, hãy bật lại JavaScript nhé.
Vậy để copy nội dung trên web đã bị khóa chuột, các bạn cần mở khóa chuột bằng cách tắt tính năng hỗ trợ JavaScript của trình duyệt là bạn có thể thao tác chuột để copy nội dung một cách bình thường. Ngoài ra, bạn có thể sử dụng thêm add-on hoặc dùng tính năng kiểm tra phần tử trang web thông qua phím F12. Dưới đây, Quantrimang.com sẽ hướng dẫn bạn cả cách tắt tính năng hỗ trợ JavaScript trên Google Chrome, Mozilla Firefox, cài add-on, sử dụng phím F12, mời các bạn cùng theo dõi nhé.
Copy nội dung website trên Chrome, Cốc Cốc
1. Cài add-on All Copy cho Chrome
Tải Enable Copy: https://chrome.google.com/webstore/detail/enable-copy/lmnganadkecefnhncokdlaohlkneihio
Cài Enable Copy cho Chrome
Truy cập trang web không cho phép sao chép nội dung
Nếu biểu tượng của add-on chưa chuyển sang màu đen, bạn click chuột vào biểu tượng của Enable Copy trên trình duyệt (đây là bước bắt buộc phải làm, để kích hoạt add-on)
Rồi, thích copy cái gì thì bạn copy thôi, có thể bôi đen, Ctrl + C hoặc bôi đen, chuột phải > Copy, đều OK nhé.
Cách này mình đã thử với một số trang và trang web của một bạn đọc comment bên dưới bài viết, đều OK.
2. Dùng allowcopy.com
Nếu ngại cài add-on lên trình duyệt bạn có thể truy cập vào trang web allowcopy.com, sau đó copy và dán link của trang web có nội dung bạn muốn copy vào khung URL > nhấn Submit. Allowcopy sẽ mở ra một trang mới với nội dung của trang web bạn dán vào, nhưng có thể copy như bình thường. Khá nhanh gọn và tiện lợi. Bạn thử xem nhé!
3. Sử dụng tính năng in để copy nội dung website:
Cảm ơn sự đóng góp của bạn đọc có Facebook là Kiên Đinh và Bo Cong đã giúp bài viết hoàn thiện hơn!
Tiếc là cách này chỉ áp dụng được trên trình duyệt Chrome, mình đã thử trên Firefox, Internet Explorer nhưng không sao chép được.
Để thực hiện, bạn chỉ cần mở trang web muốn copy, nhấn Ctrl + P hoặc dấu 3 chấm dọc ở góc trên bên phải, chọn Print. Trình duyệt sẽ cho phép xem trước trang web muốn in, bây giờ, bạn chỉ cần chọn đoạn muốn sao chép, bôi đen, Ctrl + C, rồi dán vào chỗ cần là xong.
4. Tắt tính năng hỗ trợ JavaScript trên Google Chrome
Nếu bạn ngại cài add-on trên trình duyệt thì có thể áp dụng cách tắt tính năng hỗ trợ JavaScript trên trình duyệt, tuy nhiên cách này chỉ dùng được khi trang web sử dụng đoạn mã Java để ngăn chặn sao chép, mặt khác, các mã Java khác cũng sẽ bị chặn, làm ảnh hưởng đến trải nghiệm duyệt web của bạn. Điều này có thể khắc phục bằng cách, chỉ tắt tính năng khi cần sao chép, sau khi copy xong thì lại bật lên.
Mở trình duyệt Google Chrome, nhấp vào dấu ⋮ ở góc bên trên bên phải > rồi chọn Cài đặt:
Các bạn chọn Hiển thị cài đặt nâng cao ở phía cuối.
Các bạn tìm đến phần Bảo mật và Riêng tư và chọn Cài đặt nội dung
Trong mục JavaScript các bạn gạt điều khiển ở bên phải để nó biến thành màu xám, chặn không cho các trang web chạy JavaScript là xong.
Trên các bản Chrome cũ hơn, bạn sẽ không thấy gạt điều khiển, thay vào đó là tùy chọn Không cho phép bất kỳ trang web nào chạy JavaScript, bạn hãy chọn tùy chọn này > Hoàn tất.
Lưu ý: Mình không khuyến khích làm cách này vì JavaScript là một phần không thể thiếu của các trang web, nếu bạn tắt đi sẽ khiến trang web không hiển thị được nhiều nội dung. Vì thế sau khi copy được nội dung bạn cần, hãy bật lại JavaScript nhé.
Chủ Nhật, 17 tháng 6, 2018
Security Testing - Cryptography
What is Cryptography?
Cryptography is the science to encrypt and decrypt data that enables the users to store sensitive information or transmit it across insecure networks so that it can be read only by the intended recipient.
Data which can be read and understood without any special measures is called plaintext, while the method of disguising plaintext in order to hide its substance is called encryption.
Encrypted plaintext is known as cipher text and process of reverting the encrypted data back to plain text is known as decryption.
The science of analyzing and breaking secure communication is known as cryptanalysis. The people who perform the same also known as attackers.
Cryptography can be either strong or weak and the strength is measured by the time and resources it would require to recover the actual plaintext.
Hence an appropriate decoding tool is required to decipher the strong encrypted messages.
There are some cryptographic techniques available with which even a billion computers doing a billion checks a second, it is not possible to decipher the text.
As the computing power is increasing day by day, one has to make the encryption algorithms very strong in order to protect data and critical information from the attackers.
How Encryption Works?
A cryptographic algorithm works in combination with a key (can be a word, number, or phrase) to encrypt the plaintext and the same plaintext encrypts to different cipher text with different keys.
Hence, the encrypted data is completely dependent couple of parameters such as the strength of the cryptographic algorithm and the secrecy of the key.
Cryptography Techniques
Symmetric Encryption − Conventional cryptography, also known as conventional encryption, is the technique in which only one key is used for both encryption and decryption. For example, DES, Triple DES algorithms, MARS by IBM, RC2, RC4, RC5, RC6.
Asymmetric Encryption − It is Public key cryptography that uses a pair of keys for encryption: a public key to encrypt data and a private key for decryption. Public key is published to the people while keeping the private key secret. For example, RSA, Digital Signature Algorithm (DSA), Elgamal.
Hashing − Hashing is ONE-WAY encryption, which creates a scrambled output that cannot be reversed or at least cannot be reversed easily. For example, MD5 algorithm. It is used to create Digital Certificates, Digital signatures, Storage of passwords, Verification of communications, etc.
Cryptography is the science to encrypt and decrypt data that enables the users to store sensitive information or transmit it across insecure networks so that it can be read only by the intended recipient.
Data which can be read and understood without any special measures is called plaintext, while the method of disguising plaintext in order to hide its substance is called encryption.
Encrypted plaintext is known as cipher text and process of reverting the encrypted data back to plain text is known as decryption.
The science of analyzing and breaking secure communication is known as cryptanalysis. The people who perform the same also known as attackers.
Cryptography can be either strong or weak and the strength is measured by the time and resources it would require to recover the actual plaintext.
Hence an appropriate decoding tool is required to decipher the strong encrypted messages.
There are some cryptographic techniques available with which even a billion computers doing a billion checks a second, it is not possible to decipher the text.
As the computing power is increasing day by day, one has to make the encryption algorithms very strong in order to protect data and critical information from the attackers.
How Encryption Works?
A cryptographic algorithm works in combination with a key (can be a word, number, or phrase) to encrypt the plaintext and the same plaintext encrypts to different cipher text with different keys.
Hence, the encrypted data is completely dependent couple of parameters such as the strength of the cryptographic algorithm and the secrecy of the key.
Cryptography Techniques
Symmetric Encryption − Conventional cryptography, also known as conventional encryption, is the technique in which only one key is used for both encryption and decryption. For example, DES, Triple DES algorithms, MARS by IBM, RC2, RC4, RC5, RC6.
Asymmetric Encryption − It is Public key cryptography that uses a pair of keys for encryption: a public key to encrypt data and a private key for decryption. Public key is published to the people while keeping the private key secret. For example, RSA, Digital Signature Algorithm (DSA), Elgamal.
Hashing − Hashing is ONE-WAY encryption, which creates a scrambled output that cannot be reversed or at least cannot be reversed easily. For example, MD5 algorithm. It is used to create Digital Certificates, Digital signatures, Storage of passwords, Verification of communications, etc.
Security Testing - Encoding and Decoding
What is Encoding and Decoding?
Encoding is the process of putting a sequence of characters such as letters, numbers and other special characters into a specialized format for efficient transmission.
Decoding is the process of converting an encoded format back into the original sequence of characters. It is completely different from Encryption which we usually misinterpret.
Encoding and decoding are used in data communications and storage. Encoding should NOT be used for transporting sensitive information.
URL Encoding
URLs can only be sent over the Internet using the ASCII character-set and there are instances when URL contains special characters apart from ASCII characters, it needs to be encoded. URLs do not contain spaces and are replaced with a plus (+) sign or with %20.
ASCII Encoding
The Browser (client side) will encode the input according to the character-set used in the web-page and the default character-set in HTML5 is UTF-8.
Following table shows ASCII symbol of the character and its equal Symbol and finally its replacement which can be used in URL before passing it to the server
Encoding is the process of putting a sequence of characters such as letters, numbers and other special characters into a specialized format for efficient transmission.
Decoding is the process of converting an encoded format back into the original sequence of characters. It is completely different from Encryption which we usually misinterpret.
Encoding and decoding are used in data communications and storage. Encoding should NOT be used for transporting sensitive information.
URL Encoding
URLs can only be sent over the Internet using the ASCII character-set and there are instances when URL contains special characters apart from ASCII characters, it needs to be encoded. URLs do not contain spaces and are replaced with a plus (+) sign or with %20.
ASCII Encoding
The Browser (client side) will encode the input according to the character-set used in the web-page and the default character-set in HTML5 is UTF-8.
Following table shows ASCII symbol of the character and its equal Symbol and finally its replacement which can be used in URL before passing it to the server
Security Testing - HTTPS Protocol Basics
HTTPS (Hypertext Transfer Protocol over Secure Socket Layer) or HTTP over SSL is a web protocol developed by Netscape. It is not a protocol but it is just the result of layering the HTTP on top of SSL/TLS (Secure Socket Layer/Transport Layer Security).
In short, HTTPS = HTTP + SSL
When is HTTPS Required?
When we browse, we normally send and receive information using HTTP protocol. So this leads anyone to eavesdrop on the conversation between our computer and the web server. Many a times we need to exchange sensitive information which needs to be secured and to prevent unauthorized access.
Https protocol used in the following scenarios −
- Banking Websites
- Payment Gateway
- Shopping Websites
- All Login Pages
- Email Apps
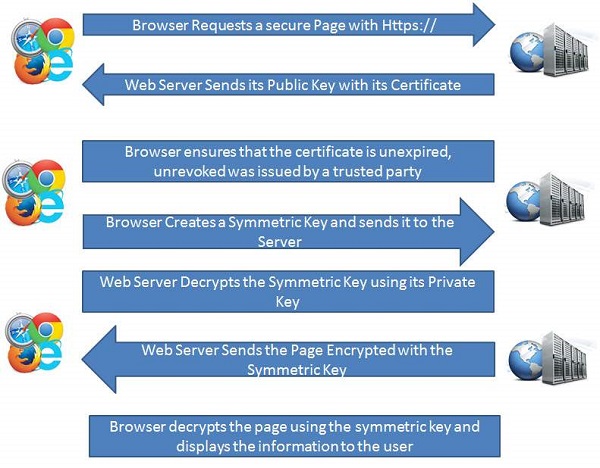
- Basic Working of HTTPS
Public key and signed certificates are required for the server in HTTPS Protocol.
Client requests for the https:// page
When using an https connection, the server responds to the initial connection by offering a list of encryption methods the webserver supports.
In response, the client selects a connection method, and the client and server exchange certificates to authenticate their identities.
After this is done, both webserver and client exchange the encrypted information after ensuring that both are using the same key, and the connection is closed.
For hosting https connections, a server must have a public key certificate, which embeds key information with a verification of the key owner's identity.
Almost all certificates are verified by a third party so that clients are assured that the key is always secure.
In short, HTTPS = HTTP + SSL
When is HTTPS Required?
When we browse, we normally send and receive information using HTTP protocol. So this leads anyone to eavesdrop on the conversation between our computer and the web server. Many a times we need to exchange sensitive information which needs to be secured and to prevent unauthorized access.
Https protocol used in the following scenarios −
- Banking Websites
- Payment Gateway
- Shopping Websites
- All Login Pages
- Email Apps
- Basic Working of HTTPS
Public key and signed certificates are required for the server in HTTPS Protocol.
Client requests for the https:// page
When using an https connection, the server responds to the initial connection by offering a list of encryption methods the webserver supports.
In response, the client selects a connection method, and the client and server exchange certificates to authenticate their identities.
After this is done, both webserver and client exchange the encrypted information after ensuring that both are using the same key, and the connection is closed.
For hosting https connections, a server must have a public key certificate, which embeds key information with a verification of the key owner's identity.
Almost all certificates are verified by a third party so that clients are assured that the key is always secure.
Security Testing - HTTP Protocol Basics
Understanding the protocol is very important to get a good grasp on security testing. You will be able to appreciate the importance of the protocol when we intercept the packet data between the webserver and the client.
HTTP Protocol
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. This is the foundation for data communication for the World Wide Web since 1990. HTTP is a generic and stateless protocol which can be used for other purposes as well using extension of its request methods, error codes, and headers.
Basically, HTTP is a TCP/IP based communication protocol, which is used to deliver data such as HTML files, image files, query results etc. over the web. It provides a standardized way for computers to communicate with each other. HTTP specification specifies how clients’ requested data are sent to the server, and how servers respond to these requests.
Basic Features
There are following three basic features which make HTTP a simple yet powerful protocol −
HTTP is connectionless − The HTTP client, i.e., the browser initiates an HTTP request. After making a request, the client disconnects from the server and waits for a response. The server processes the request and re-establishes the connection with the client to send the response back.
HTTP is media independent − Any type of data can be sent by HTTP as long as both the client and server know how to handle the data content. This is required for client as well as server to specify the content type using appropriate MIME-type.
HTTP is stateless − HTTP is a connectionless and this is a direct result that HTTP is a stateless protocol. The server and client are aware of each other only during a current request. Afterwards, both of them forget about each other. Due to this nature of the protocol, neither the client nor the browser can retain information between different requests across the web pages.
HTTP/1.0 uses a new connection for each request/response exchange whereas HTTP/1.1 connection may be used for one or more request/response exchanges.
Architecture
The following diagram shows a very basic architecture of a web application and depicts where HTTP resides −
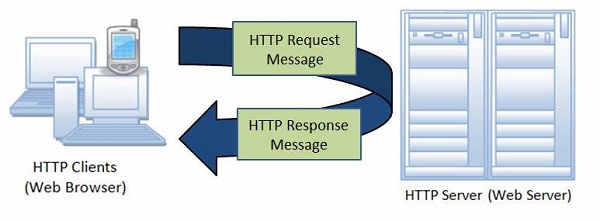
The HTTP protocol is a request/response protocol based on the client/server architecture where web browser, robots, and search engines etc. act as HTTP clients and the web server acts as a server.
Client − The HTTP client sends a request to the server in the form of a request method, URI, and protocol version, followed by a MIME-like message containing request modifiers, client information, and possible body content over a TCP/IP connection.
Server − The HTTP server responds with a status line, including the protocol version of the message and a success or error code, followed by a MIME-like message containing server information, entity meta information, and possible entity-body content.
HTTP – Disadvantages
- HTTP is not a completely secured protocol.
- HTTP uses port 80 as default port for communication.
- HTTP operates at the application Layer. It needs to create multiple connections for data transfer, which increases administration overheads.
- No encryption/digital certificates are required for using HTTP.
HTTP Protocol
The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. This is the foundation for data communication for the World Wide Web since 1990. HTTP is a generic and stateless protocol which can be used for other purposes as well using extension of its request methods, error codes, and headers.
Basically, HTTP is a TCP/IP based communication protocol, which is used to deliver data such as HTML files, image files, query results etc. over the web. It provides a standardized way for computers to communicate with each other. HTTP specification specifies how clients’ requested data are sent to the server, and how servers respond to these requests.
Basic Features
There are following three basic features which make HTTP a simple yet powerful protocol −
HTTP is connectionless − The HTTP client, i.e., the browser initiates an HTTP request. After making a request, the client disconnects from the server and waits for a response. The server processes the request and re-establishes the connection with the client to send the response back.
HTTP is media independent − Any type of data can be sent by HTTP as long as both the client and server know how to handle the data content. This is required for client as well as server to specify the content type using appropriate MIME-type.
HTTP is stateless − HTTP is a connectionless and this is a direct result that HTTP is a stateless protocol. The server and client are aware of each other only during a current request. Afterwards, both of them forget about each other. Due to this nature of the protocol, neither the client nor the browser can retain information between different requests across the web pages.
HTTP/1.0 uses a new connection for each request/response exchange whereas HTTP/1.1 connection may be used for one or more request/response exchanges.
Architecture
The following diagram shows a very basic architecture of a web application and depicts where HTTP resides −
The HTTP protocol is a request/response protocol based on the client/server architecture where web browser, robots, and search engines etc. act as HTTP clients and the web server acts as a server.
Client − The HTTP client sends a request to the server in the form of a request method, URI, and protocol version, followed by a MIME-like message containing request modifiers, client information, and possible body content over a TCP/IP connection.
Server − The HTTP server responds with a status line, including the protocol version of the message and a success or error code, followed by a MIME-like message containing server information, entity meta information, and possible entity-body content.
HTTP – Disadvantages
- HTTP is not a completely secured protocol.
- HTTP uses port 80 as default port for communication.
- HTTP operates at the application Layer. It needs to create multiple connections for data transfer, which increases administration overheads.
- No encryption/digital certificates are required for using HTTP.
[Guide fo C] Types of Function calls in C
Functions are called by their names, we all know that, then what is this tutorial for? Well if the function does not have any arguments, then to call a function you can directly use its name. But for functions with arguments, we can call a function in two different ways, based on how we specify the arguments, and these two ways are:
- Call by Value
- Call by Reference
- Call by Value
Calling a function by value means, we pass the values of the arguments which are stored or copied into the formal parameters of the function. Hence, the original values are unchanged only the parameters inside the function changes.
Call by Reference
In call by reference we pass the address(reference) of a variable as argument to any function. When we pass the address of any variable as argument, then the function will have access to our variable, as it now knows where it is stored and hence can easily update its value.
In this case the formal parameter can be taken as a reference or a pointer(don't worry about pointers, we will soon learn about them), in both the cases they will change the values of the original variable.
NOTE: If you do not have any prior knowledge of pointers, do study Pointers first. Or just go over this topic and come back again to revise this, once you have learned about pointers.
- Call by Value
- Call by Reference
- Call by Value
Calling a function by value means, we pass the values of the arguments which are stored or copied into the formal parameters of the function. Hence, the original values are unchanged only the parameters inside the function changes.
#include<stdio.h>
void calc(int x);
int main()
{
int x = 10;
calc(x);
// this will print the value of 'x'
printf("\nvalue of x in main is %d", x);
return 0;
}
void calc(int x)
{
// changing the value of 'x'
x = x + 10 ;
printf("value of x in calc function is %d ", x);
}
value of x in main is 10
In this case, the actual variable x is not changed. This is because we are passing the argument by value, hence a copy of x is passed to the function, which is updated during function execution, and that copied value in the function is destroyed when the function ends(goes out of scope). So the variable x inside the main() function is never changed and hence, still holds a value of 10.
But we can change this program to let the function modify the original x variable, by making the function calc() return a value, and storing that value in x.
In this case, the actual variable x is not changed. This is because we are passing the argument by value, hence a copy of x is passed to the function, which is updated during function execution, and that copied value in the function is destroyed when the function ends(goes out of scope). So the variable x inside the main() function is never changed and hence, still holds a value of 10.
But we can change this program to let the function modify the original x variable, by making the function calc() return a value, and storing that value in x.
#include<stdio.h>
int calc(int x);
int main()
{
int x = 10;
x = calc(x);
printf("value of x is %d", x);
return 0;
}
int calc(int x)
{
x = x + 10 ;
return x;
}Call by Reference
In call by reference we pass the address(reference) of a variable as argument to any function. When we pass the address of any variable as argument, then the function will have access to our variable, as it now knows where it is stored and hence can easily update its value.
In this case the formal parameter can be taken as a reference or a pointer(don't worry about pointers, we will soon learn about them), in both the cases they will change the values of the original variable.
#include<stdio.h>
void calc(int *p); // functin taking pointer as argument
int main()
{
int x = 10;
calc(&x); // passing address of 'x' as argument
printf("value of x is %d", x);
return(0);
}
void calc(int *p) //receiving the address in a reference pointer variable
{
/*
changing the value directly that is
stored at the address passed
*/
*p = *p + 10;
}NOTE: If you do not have any prior knowledge of pointers, do study Pointers first. Or just go over this topic and come back again to revise this, once you have learned about pointers.
[Guide for C] Error Handling in C
C language does not provide any direct support for error handling. However a few methods and variables defined in error.h header file can be used to point out error using the return statement in a function. In C language, a function returns -1 or NULL value in case of any error and a global variable errno is set with the error code. So the return value can be used to check error while programming.
What is errno?
Whenever a function call is made in C language, a variable named errno is associated with it. It is a global variable, which can be used to identify which type of error was encountered while function execution, based on its value. Below we have the list of Error numbers and what does they mean.
C language uses the following functions to represent error messages associated with errno:
perror(): returns the string passed to it along with the textual represention of the current errno value.
strerror() is defined in string.h library. This method returns a pointer to the string representation of the current errno value.
Time for an Example
Here exit function is used to indicate exit status. Its always a good practice to exit a program with a exit status. EXIT_SUCCESS and EXIT_FAILURE are two macro used to show exit status. In case of program coming out after a successful operation EXIT_SUCCESS is used to show successful exit. It is defined as 0. EXIT_Failure is used in case of any failure in the program. It is defined as -1.
Division by Zero
There are some situation where nothing can be done to handle the error. In C language one such situation is division by zero. All you can do is avoid doing this, becasue if you do so, C language is not able to understand what happened, and gives a runtime error.
Best way to avoid this is, to check the value of the divisor before using it in the division operations. You can use if condition, and if it is found to be zero, just display a message and return from the function.
What is errno?
Whenever a function call is made in C language, a variable named errno is associated with it. It is a global variable, which can be used to identify which type of error was encountered while function execution, based on its value. Below we have the list of Error numbers and what does they mean.
| errno value | Error |
|---|---|
| 1 | Operation not permitted |
| 2 | No such file or directory |
| 3 | No such process |
| 4 | Interrupted system call |
| 5 | I/O error |
| 6 | No such device or address |
| 7 | Argument list too long |
| 8 | Exec format error |
| 9 | Bad file number |
| 10 | No child processes |
| 11 | Try again |
| 12 | Out of memory |
| 13 | Permission denied |
C language uses the following functions to represent error messages associated with errno:
perror(): returns the string passed to it along with the textual represention of the current errno value.
strerror() is defined in string.h library. This method returns a pointer to the string representation of the current errno value.
Time for an Example
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main ()
{
FILE *fp;
/*
If a file, which does not exists, is opened,
we will get an error
*/
fp = fopen("IWillReturnError.txt", "r");
printf("Value of errno: %d\n ", errno);
printf("The error message is : %s\n", strerror(errno));
perror("Message from perror");
return 0;
}
The error message is: No such file or directory
Message from perror: No such file or directory
Other ways of Error Handling
We can also use Exit Status constants in the exit() function to inform the calling function about the error. The two constant values available for use are EXIT_SUCCESS and EXIT_FAILURE. These are nothing but macros defined stdlib.h header file.
Other ways of Error Handling
We can also use Exit Status constants in the exit() function to inform the calling function about the error. The two constant values available for use are EXIT_SUCCESS and EXIT_FAILURE. These are nothing but macros defined stdlib.h header file.
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
#include <string.h>
extern int errno;
void main()
{
char *ptr = malloc( 1000000000UL); //requesting to allocate 1gb memory space
if (ptr == NULL) //if memory not available, it will return null
{
puts("malloc failed");
puts(strerror(errno));
exit(EXIT_FAILURE); //exit status failure
}
else
{
free( ptr);
exit(EXIT_SUCCESS); //exit status Success
}
}Here exit function is used to indicate exit status. Its always a good practice to exit a program with a exit status. EXIT_SUCCESS and EXIT_FAILURE are two macro used to show exit status. In case of program coming out after a successful operation EXIT_SUCCESS is used to show successful exit. It is defined as 0. EXIT_Failure is used in case of any failure in the program. It is defined as -1.
Division by Zero
There are some situation where nothing can be done to handle the error. In C language one such situation is division by zero. All you can do is avoid doing this, becasue if you do so, C language is not able to understand what happened, and gives a runtime error.
Best way to avoid this is, to check the value of the divisor before using it in the division operations. You can use if condition, and if it is found to be zero, just display a message and return from the function.
[Guide for C] Type of User-defined Functions in C
There can be 4 different types of user-defined functions, they are:
- Function with no arguments and no return value
- Function with no arguments and a return value
- Function with arguments and no return value
- Function with arguments and a return value
Below, we will discuss about all these types, along with program examples.
Function with no arguments and no return value
Such functions can either be used to display information or they are completely dependent on user inputs.
Below is an example of a function, which takes 2 numbers as input from user, and display which is the greater number.
Function with no arguments and a return value
We have modified the above example to make the function greatNum() return the number which is greater amongst the 2 input numbers.
- Function with no arguments and no return value
- Function with no arguments and a return value
- Function with arguments and no return value
- Function with arguments and a return value
Below, we will discuss about all these types, along with program examples.
Function with no arguments and no return value
Such functions can either be used to display information or they are completely dependent on user inputs.
Below is an example of a function, which takes 2 numbers as input from user, and display which is the greater number.
#include<stdio.h>
void greatNum(); // function declaration
int main()
{
greatNum(); // function call
return 0;
}
void greatNum() // function definition
{
int i, j;
printf("Enter 2 numbers that you want to compare...");
scanf("%d%d", &i, &j);
if(i > j) {
printf("The greater number is: %d", i);
}
else {
printf("The greater number is: %d", j);
}
}Function with no arguments and a return value
We have modified the above example to make the function greatNum() return the number which is greater amongst the 2 input numbers.
#include<stdio.h>
int greatNum(); // function declaration
int main()
{
int result;
result = greatNum(); // function call
printf("The greater number is: %d", result);
return 0;
}
int greatNum() // function definition
{
int i, j, greaterNum;
printf("Enter 2 numbers that you want to compare...");
scanf("%d%d", &i, &j);
if(i > j) {
greaterNum = i;
}
else {
greaterNum = j;
}
// returning the result
return greaterNum;
}
Đăng ký:
Nhận xét (Atom)